Distributed Computing
Introduction
Definition
of Distributed Systems
1. Collection of independent entities cooperation to
collectively solve a task.
2. Autonomous processors communicating over a communication
network
Characterization
of Distributed Systems
•
Crash
of a single computer does not inhibit normal operation
•
Computers
•
Not
sharing common memory, common clock
•
Communicate
by message passing over a network
•
Run
their own operating systems
•
Semi-autonomous
•
Loosely
coupled
•
Collection
of independent computers
•
Appearing
to users as a single coherent system
•
Describes
a wide range of computers
•
Weakly
coupled systems like WAN's
•
Strongly
coupled systems like LAN's
•
Very
strongly coupled systems like multiprocessor systems
Features
of Distributed System
•
No
common physical clock
•
Introduces
“distribution” element into the system
•
Gives
rise to asynchrony among processors
•
No shared memory
•
Absence of common physical clock
•
Requires message passing for
communication
•
Abstraction of common address may be
provided via distributed shared memory abstraction.
•
Geographical seperation
•
Processors are geographically wide apart
•
Processors may reside on a WAN
•
Processors on a LAN – small distributed
system
•
Network/Cluster of Workstations
(NOW/COW) configuration – processors connected on a LAN
•
Popularity of NOW – emergence of
low-cost high-speed off-the-shelf processors
•
Google search engine - based on NOW
architecture
•
Autonomy and heterogeneity
•
Loosely coupled processors
•
Different processor speeds
•
Different operating systems
•
Processors are not part of a dedicated
system
•
Cooperate with one another
•
May offer services
•
May solve a problem jointly
 Distributed System Model
Distributed System Model Relation between Software Components
Relation between Software Components
Interaction
of the software components
•
Distributed
execution –
•
execution
of processes across distributed system
•
goal
– collaboratively achieve a common goal
•
alternatively
known as computation/run
•
Middleware
–
•
distributed software
•
drives
the distributed system
•
provides
transparency of heterogeneity at platform level
•
User
code contains primitives and calls to functions defined in libraries of
middleware level
•
Several
libraries exist for invoking primitives for common functions of middleware
layer
•
Middleware
standards:
•
Common
Object Request Broker Architecture (CORBA)
•
developed
by Object Management Group (OMG)
•
Remote
Procedure Call (RPC) mechanism
•
Distributed
Component Object Model (DCOM)
•
Remote
Method Invocation (RMI)
•
Message
Passing Interface (MPI)
CORBA(Common Object Request Broker Architecture)
•
Provides
interoperability among distributed objects
•
Enables
exchange of information
•
Independent
of
•
Hardware
platforms
•
Programming
languages
•
Operating
systems
Design specification of Object Request Broker (ORB)
ORB: Mechanism
required for distributed objects to communicate with one another either locally
or on remote devices
• Written
in different languages, or at different locations on a network


RPC (Remote Procedure Call)
•
Called
procedure code may reside on a remote machine
•
Works
like a local procedure call
•
Steps:
•
Sends
message across n/w to invoke remote procedure
•
Remote
procedure completes execution
•
Sends
back a reply
Motivation for Distributed System
•
Inherent distributed computation
•
applications like funds transfer
•
reaching a consensus among
geographically distributed parties
•
Resource sharing
•
Peripherals, data sets in databases,
libraries, data
•
Resources can’t be replicated at all
sites
•
Should not be present at a single site à creates single
point of failure
•
Segregate resources at multiple sites
•
Increases reliability
•
Access to remote resources
•
Sensitive data/resources may remain
centralized
•
Eg., payroll data, supercomputers
•
Such resources need to be remotely
accessed
•
Encouraged development of distributed
protocols and middleware.
•
Increased performance/cost ratio
•
Due to resource sharing and accessing
geographically remote data & resources
•
Task can be partitioned across different
computers
•
Better performance/cost ratio than
parallel machines
•
Particularly true for NOW configuration
•
Reliability
•
Resource replication
•
No single point of failure
•
All sites are not likely to
crash/malfunction at the same time
•
Requirements of reliability
•
Availability
•
Integrity
•
Fault tolerance
•
Scalability
•
Processors are connected by wide-area
network
•
New processors may be easily added
•
Addition of more processors does not
create bottleneck for the communication network.
•
Modularity and incremental expandability
•
Heterogenous processors may be added
•
Does not affect performance if
processors are running the same middleware algorithm
•
Existing processors can also be replaced
Parallel Systems
Multiprocessor systems (direct access to shared memory, UMA
model)
E.g., Omega, Butterfly, Clos, shuffle-exchange networks
Multicomputer parallel systems (no direct access to shared
memory, NUMA model)
E.g., NYU Ultracomputer, CM*
Connection Machine, IBM Blue gene
Array processors (collocated, tightly coupled, common system
clock)
E.g., DSP applications.
UMA Model
·
Direct
access to shared memory
·
Forms
a common address space
·
Access latency - waiting time to complete an access to any memory
location from any processor
·
Access
latency is same for all processors
·
Processors -- Remain
in close proximity , Connected
by an interconnection network
 M – Memory, P
- Processor
M – Memory, P
- Processor
•
Interprocess Communication occurs
through
• read and
write operations on shared memory
• Message
passing primitives provided by MPI
•
Processors are of same type
•
Remain within same physical
box/container with shared memory
•
Processors run the same operating system
•
Hardware & software are very tightly
coupled
•
Interconnection network to access memory
may be
• Bus
• Multistage
switch (with regular & symmetric design) – greater efficiency
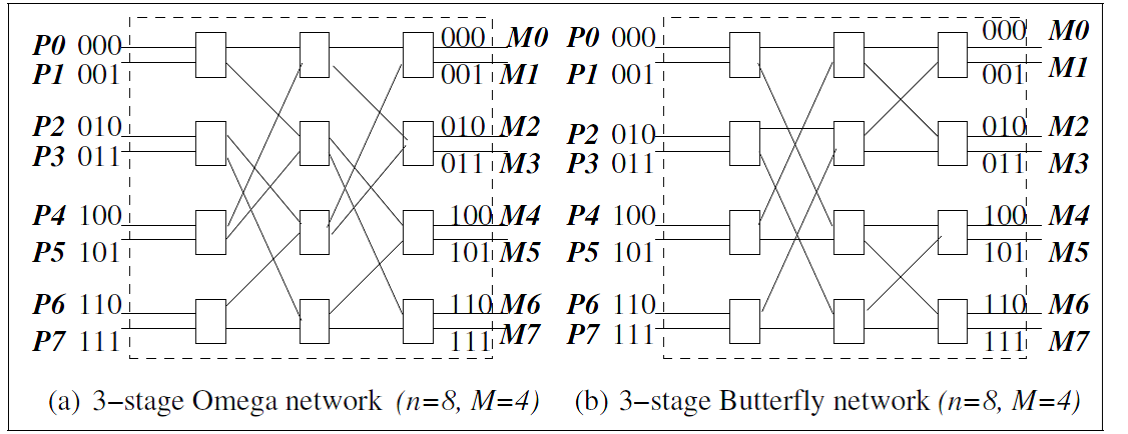 Omega, Butterfly Interconnections
Omega, Butterfly Interconnections
Interconnection
networks for shared memory multiprocessor systems
(a) Omega network
(b) Buttery
network.
·
Multi-stage
networks formed
by 2 x 2 switching elements.Data
can be sent on any one of the input wires. Data
is switched to upper or lower output wire. Collision
occurs when data from both input wires is routed to same output wire at the
same step
·
Buffering
& interconnection design techniques address collisions
·
n-input
and n-output network uses:
o
log(n)
stages
o
log(n)
bits for addressing
·
Routing
at stage k uses the kth bit
·
Multi-stage
networks
·
can
be constructed recursively or iteratively
·
interconnection pattern between any two stages can be
expressed using an iterative or a recursive generating
function
Omega Network
·
n
processors, n memory banks
·
log
n stages
·
(n/2)log(n)
switching elements of size 2x2
·
Interconnection
function: Output i of a stage is connected to input j of next stage:
·
j
= 2i, for 0 ≤ i ≤ n/2 – 1
= 2i + 1 – n, for
n/2 ≤ i ≤ n – 1
·
left-rotation
operation on the binary representation of i to get j
·
upper
(lower) input lines for a switch in stage k comes in sequential order from the
upper (lower) half of the switches in stage k - 1

For any stage
for 0 ≤ i ≤ 3, output i is connected to input 2i of
next stage
for 4 ≤ i ≤ 7, output i is connected to input 2i + 1 –
n of next stage
·
Routing
function: from input line i to output line j
·
considers
j and stage number s, s ϵ [0, log(n) – 1]
·
route
to destination j
o
if
(s + 1)th MSB of j = 0 then route on upper wire
o
else
[i.e., (s + 1)th MSB of j = 1] then route on lower wire.
Butterfly Network
·
Interconnection
function depends on n and stage number s
·
No.
of switches per stage M = n/2
·
Switch
is denoted as <x, s> , x ϵ [0, M – 1], s ϵ [0, log(n) -1]
·
An
edge from switch <x, s> to switch <y, s + 1> exists if
- x = y or,
- (s + 1)th MSB of (x XOR y) is 1
- for stage s, rule is applied for M/2s switches

·
n
= 8, M = 4, s = 0,…,2
·
interconnection pattern is between s = 0 and s = 1 and
between s = 1 and s = 2
·
x
= 0 to 3 (2-bit string)
·
for s = 0, first output line from switch 00 goes to
the input line of switch 00 of stage s =1
·
for
s = 0, second output line of switch 00 goes to input line of switch 10 of stage
s = 1
·
x
= 01 has one output line go to an input line of switch 11 in stage s = 1
·
for
stage s = 1 connecting to stage s = 2, apply the rules considering M/21
= M/2 switches
·
i.e.,
build two butterflies of size M/2 – the “upper half” and the “lower half”
switches
·
recursion
terminates for M/2s = 1, when there is a single switch
·
In
a stage s switch,
- if the (s+1)th MSB of j is 0, the data is routed to the upper output wire
- otherwise it is routed to the lower output wire
- For Butterfly and Omega networks, paths from different inputs to any one output constitute a spanning tree
- Collisions occur when data is destined to the same output line.
Multicomputer Parallel Systems
Multiple processors do not have direct access to shared memory. Memory of multiple processors may or may not form a common address space,usually do not have a common clock. Processors are in close physical proximity and very tightly coupled (homogenous hardware and software) connected by an interconnection network communicate either via a common address space or via message-passing.
eg., NYU Ultracomputer, Sequent shared memory machines, CM* Connection machine
NUMA Model
·
NUMA - non-uniform memory access
architecture.
· Multicomputer system has
a common address space, latency to access various shared memory locations from the
different processors varies

Comments
Post a Comment